
Databricks bergerak cepat memperluas integrasi AI generatif ke dalam platform analisis data-nya, mengikuti gelombang kebutuhan perusahaan yang ingin membawa kecerdasan buatan dari sekadar eksperimen menuju sistem produksi yang aman. Di banyak organisasi, data tersebar di data lake, warehouse, sistem streaming, hingga arsip dokumen; sementara tim produk menuntut pengalaman baru: tanya-jawab berbasis pengetahuan internal, otomatisasi laporan, hingga agen yang bisa mengeksekusi tindakan melalui API. Taruhannya tidak kecil: ketika model makin canggih, perusahaan justru makin khawatir soal tata kelola, kebocoran informasi, dan kualitas jawaban. Di sinilah Databricks mencoba menempatkan diri sebagai “jalan tengah” antara inovasi dan kontrol, dengan menggabungkan aset data, model, agen, serta pipeline operasional di satu alur kerja.
Perkembangan terbaru—termasuk kerja sama strategis untuk menghadirkan model-model mutakhir seperti GPT-5 secara native—mencerminkan perubahan arah industri: bukan lagi “model mana yang paling pintar”, melainkan “bagaimana model bekerja dekat dengan data perusahaan secara terukur, terpantau, dan patuh kebijakan”. Artikel ini menelusuri bagaimana Databricks merapikan fondasi GenAI: dari desain aplikasi, evaluasi, dan observabilitas, hingga agentic workflows yang menembus batas chatbot biasa. Di sepanjang pembahasan, kita mengikuti contoh hipotetis perusahaan ritel “NusantaraMart” yang mencoba mengubah big data menjadi layanan pelanggan dan operasi yang lebih cerdas lewat otomatisasi—tanpa mengorbankan keamanan dan akurasi.
Ekspansi AI generatif di Databricks: dari analisis data ke produk berbasis agen
Dalam beberapa tahun terakhir, Databricks dikenal karena kemampuan menyatukan data lake dan data warehouse untuk kebutuhan analisis data dan pembelajaran mesin. Namun saat AI generatif menjadi arus utama, tuntutan perusahaan bergeser: bukan hanya menganalisis apa yang terjadi, tetapi juga “menciptakan” respons, ringkasan, rekomendasi, dan tindakan operasional secara otomatis. Ekspansi Databricks bisa dipahami sebagai perluasan peran: dari platform analitik menjadi platform data + AI yang siap melayani aplikasi interaktif dan agen otonom.
Bagi NusantaraMart, perubahan ini terasa nyata. Dulu, tim data hanya menyiapkan dashboard penjualan dan model peramalan permintaan. Kini, tim layanan pelanggan meminta asisten yang dapat menjawab pertanyaan pengembalian barang berdasarkan kebijakan terbaru, riwayat transaksi, dan percakapan sebelumnya. Tim gudang ingin agen yang bisa menyusun prioritas picking berdasarkan pesanan real-time. Keduanya membutuhkan sistem yang bukan sekadar menjalankan model, melainkan menghubungkan model dengan sumber data dan alat tindakan—di bawah aturan akses yang jelas.
Databricks memposisikan aplikasi GenAI dalam beberapa bentuk yang “akrab” untuk enterprise. Pertama, aplikasi obrolan yang langsung menghadap pengguna, yang dalam praktiknya menuntut UI, autentikasi, logging, dan batasan akses. Kedua, endpoint API untuk agen yang dipanggil oleh aplikasi lain, misalnya aplikasi helpdesk internal. Ketiga, fungsi yang bisa dipakai analis melalui SQL, sehingga tim BI dapat menambahkan ringkasan otomatis, klasifikasi teks, atau ekstraksi entitas langsung di kueri. Pola ini penting karena organisasi jarang punya satu jalur adopsi; mereka butuh banyak pintu masuk agar setiap peran—analis, data engineer, dan pengembang—bisa bergerak sesuai ritme kerja mereka.
Ekspansi ini juga terkait dengan ekosistem model. Databricks tidak hanya mengandalkan satu penyedia, melainkan membuka jalan untuk berbagai model fondasi, termasuk model open-weight. Dalam konteks enterprise, pilihan model sering dipengaruhi oleh biaya inferensi, latensi, kebutuhan bahasa, dan kebijakan residensi data. Ketika perusahaan ingin bereksperimen dengan model yang lebih kecil untuk tugas rutin dan mengaktifkan model yang lebih besar untuk kasus kompleks, platform perlu memfasilitasi orkestrasi itu tanpa membuat tim menulis ulang semuanya.
Menariknya, kerja sama Databricks dengan OpenAI untuk menghadirkan model terbaru seperti GPT-5 sebagai produk native memperlihatkan strategi “mendekatkan model ke data”. Kesepakatan bernilai minimal ratusan juta dolar (dengan komitmen pembayaran minimal yang menjadi risiko Databricks bila adopsi melambat) adalah sinyal bahwa Databricks melihat permintaan enterprise sangat agresif. Bagi pelanggan besar—misalnya perusahaan pembayaran—akses langsung dari lingkungan Databricks memotong friksi integrasi, mempercepat prototyping, dan mempermudah audit karena jalur data dan pemanggilan model berada di satu tempat.
Di level praktis, ekspansi ini bukan soal menambahkan tombol “Generate”. Ini tentang menyiapkan jalur produksi: data masuk, konteks dipilih, model dipanggil, keluaran divalidasi, lalu tindakan dijalankan—semuanya harus tercatat. Jika satu komponen tidak terkelola, perusahaan akan kembali ke “spaghetti AI”: prompt tersebar di notebook, kunci API tersimpan sembarangan, dan kualitas jawaban sulit dilacak. Insight kuncinya: integrasi GenAI yang baik selalu dimulai dari desain operasional, bukan dari demo yang memukau.

Arsitektur platform GenAI Databricks: menyatukan data, model, agen, dan tata kelola
Platform GenAI yang matang menuntut komponen yang saling terhubung rapat. Di satu sisi ada aset data: tabel transaksi, file log, dokumen kebijakan, indeks vektor untuk pencarian semantik, dan pipeline pemrosesan. Di sisi lain ada aset AI: model, agen, aplikasi, dan endpoint penyajian. Databricks mendorong pendekatan terpadu agar organisasi tidak perlu menambal solusi dari banyak tempat. Dalam konteks transformasi digital, ini penting karena biaya terbesar sering bukan komputasi, melainkan koordinasi: siapa boleh akses data apa, siapa mengubah prompt, siapa menyetujui model baru, dan bagaimana rollback dilakukan ketika hasil memburuk.
Dalam skenario NusantaraMart, dokumen kebijakan pengembalian barang berada di repositori dokumen, sementara data transaksi ada di warehouse, dan chat pelanggan tersimpan di sistem tiket. Jika tim ingin membangun asisten yang menjawab dengan akurat, mereka perlu dua jenis retrieval: pencarian semantik untuk menemukan paragraf kebijakan relevan, dan retrieval terstruktur untuk memeriksa status pesanan. Databricks mengarahkan pola ini agar berada dalam satu kerangka: retrieval semantik melalui indeks vektor, retrieval terstruktur melalui SQL atau API, lalu “brain” model GenAI merangkai jawaban yang sesuai konteks.
Tata kelola menjadi pembeda utama. Dengan konsep katalog terpusat untuk aset data dan AI, perusahaan dapat menerapkan kebijakan akses yang konsisten: siapa yang boleh melihat kolom sensitif, dataset mana yang boleh dipakai untuk fine-tuning, dan apakah keluaran model boleh menyertakan informasi tertentu. Ini memotong risiko “shadow AI”, yaitu ketika unit bisnis membuat bot sendiri memakai data ekspor. Di level kebijakan, organisasi bisa membedakan akses: agen layanan pelanggan boleh membaca ringkasan pesanan, tetapi tidak boleh melihat nomor kartu atau detail alamat lengkap.
Selain data governance, governance pada endpoint model juga krusial. Banyak perusahaan mengalami “kebocoran tak sengaja” bukan karena data dicuri, melainkan karena prompt atau konteks memasukkan informasi yang seharusnya tidak tampil. Dengan mekanisme gateway dan kontrol di depan pemanggilan model, perusahaan bisa menetapkan aturan seperti redaksi PII, pembatasan domain, atau audit untuk setiap request. Pendekatan ini selaras dengan praktik enterprise: sistem harus aman secara default, bukan aman karena pengguna diingatkan.
Arsitektur terpadu juga mempercepat pengembangan lintas peran. Analis data yang terbiasa dengan SQL dapat memanfaatkan fungsi AI untuk tugas seperti klasifikasi tiket atau ringkasan catatan rapat, sementara data engineer menjaga kualitas pipeline. Tim aplikasi membangun UI obrolan atau API, dan tim keamanan melakukan review kebijakan—semuanya tetap memakai satu sumber kebenaran. Hasilnya bukan hanya kecepatan, tetapi konsistensi.
Pada 2026, tren multimodal (teks+gambar+audio) makin terasa. Banyak organisasi ritel ingin agen yang dapat membaca foto barang rusak, memadankan dengan katalog, lalu membuat keputusan penggantian. Ide ini paralel dengan evolusi pencarian multimodal di produk konsumen. Untuk gambaran arah tersebut, pembaca bisa melihat konteks yang lebih luas lewat pembahasan tentang pencarian AI multimodal yang menunjukkan bagaimana antarmuka manusia-mesin bergeser dari kata kunci menjadi dialog berbasis konteks. Insight kuncinya: platform yang menyatukan data terstruktur dan tidak terstruktur akan menang dalam perlombaan GenAI enterprise.
Di tingkat implementasi, organisasi sebaiknya memetakan aset dan kontrol sejak awal. Berikut contoh prioritas yang sering dipakai ketika membangun platform GenAI di Databricks:
- Inventaris data: identifikasi tabel, dokumen, dan log yang paling sering dibutuhkan aplikasi GenAI.
- Kebijakan akses: tetapkan aturan untuk PII, data rahasia, dan jalur audit untuk pemanggilan model.
- Lapisan retrieval: bangun indeks vektor dan koneksi SQL/API untuk konteks yang kaya.
- Standar prompt dan evaluasi: definisikan template, metrik kualitas, dan proses persetujuan perubahan.
- Operasionalisasi: siapkan monitoring, fallback, serta prosedur respons insiden.
Dengan langkah seperti ini, ekspansi GenAI tidak mengorbankan kendali. Tema berikutnya menguji titik paling rapuh: bagaimana mengevaluasi sistem yang jawabannya terbuka dan sering “terlihat meyakinkan” meski salah.
Evaluasi dan observabilitas GenAI di Databricks: MLflow, umpan balik manusia, dan metrik yang bisa diaudit
Evaluasi pada AI generatif bukan sekadar akurasi seperti pada model klasifikasi tradisional. Jawaban bisa benar dengan banyak cara, dan salah dengan cara yang terdengar sangat masuk akal. Dalam aplikasi layanan pelanggan NusantaraMart, satu kalimat yang keliru tentang kebijakan pengembalian dapat memicu biaya kompensasi dan merusak reputasi. Karena itu, ekspansi Databricks menekankan evaluasi sebagai kemampuan inti, bukan fitur tambahan. Organisasi yang sukses biasanya menggabungkan evaluasi otomatis, tinjauan ahli, dan pemantauan produksi yang berkelanjutan.
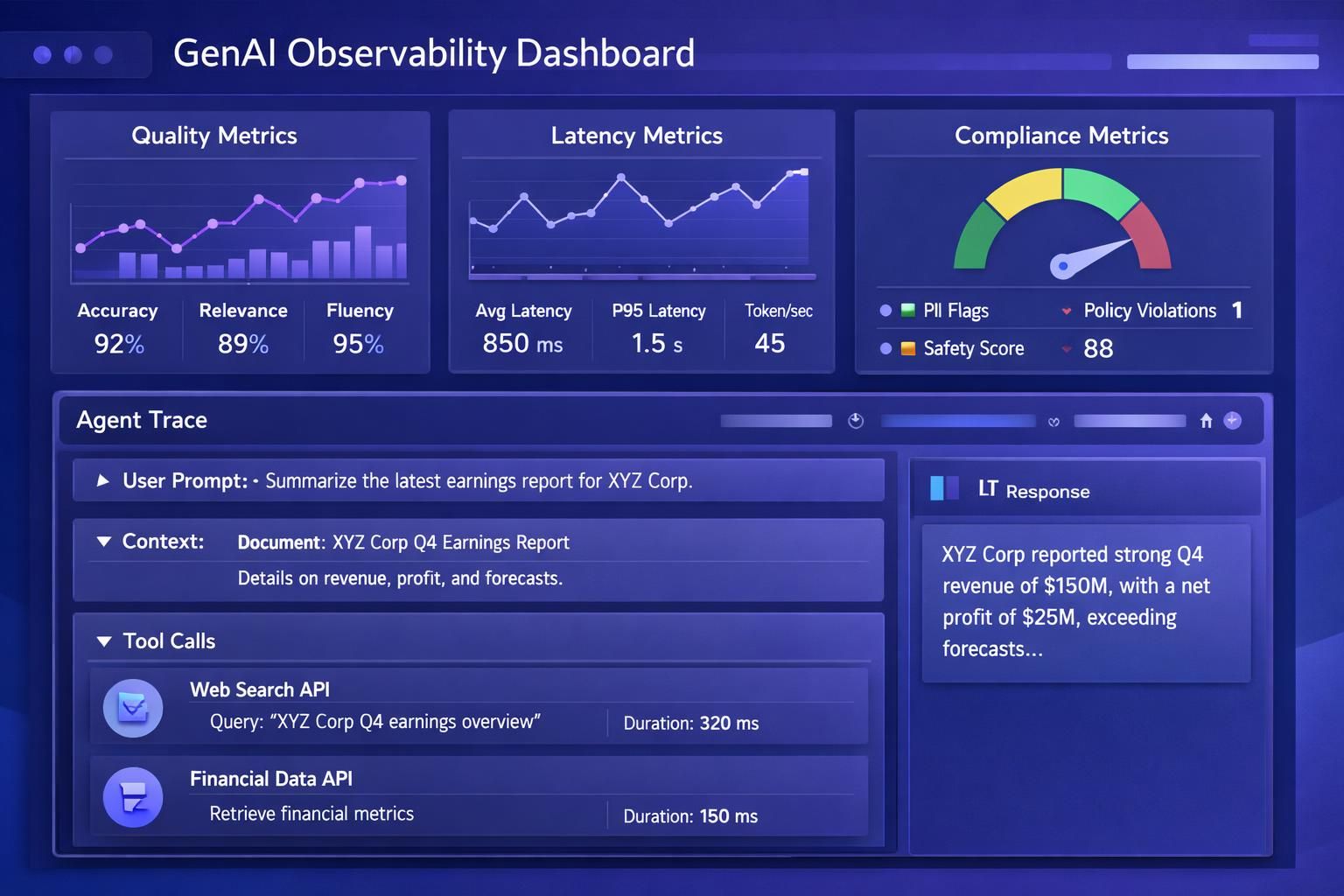
Di Databricks, fondasi evaluasi sering bertumpu pada MLflow versi terbaru dan alat terkait untuk pelacakan, penilaian, dan observabilitas. Praktiknya begini: setiap percakapan agen dicatat sebagai jejak—prompt, konteks yang diambil, alat yang dipanggil, parameter, latensi, dan output. Dari sini, tim bisa menganalisis mengapa jawaban tertentu muncul. Misalnya, bila agen menyebut kebijakan lama, tim dapat melihat bahwa retrieval vektor menarik dokumen yang sudah kedaluwarsa karena pipeline indeks belum diperbarui. Tanpa jejak seperti ini, debugging menjadi tebak-tebakan.
Evaluasi otomatis sering memanfaatkan “AI untuk menilai AI”. Model penilai dapat memeriksa apakah jawaban menyertakan referensi kebijakan yang benar, apakah ada halusinasi (klaim tanpa dukungan), atau apakah gaya bahasa sesuai standar brand. Namun evaluasi otomatis tidak boleh berdiri sendiri. Umpan balik manusia—baik dari ahli kebijakan maupun agen CS yang berinteraksi dengan pelanggan—berfungsi sebagai kebenaran dasar untuk mengkalibrasi skor otomatis. Kombinasi ini memungkinkan metrik yang lebih stabil: tidak terlalu subyektif, tetapi juga tidak buta konteks.
Di tingkat metrik, perusahaan biasanya membagi evaluasi menjadi beberapa lapisan. Lapisan pertama adalah kualitas jawaban: relevansi, kelengkapan, dan ketepatan fakta. Lapisan kedua adalah keselamatan dan kepatuhan: apakah ada PII, apakah menyarankan tindakan yang dilarang, apakah melanggar batasan domain. Lapisan ketiga adalah pengalaman: latensi, tingkat eskalasi ke manusia, dan kepuasan pengguna. Databricks mendorong agar metrik ini bisa diaudit, karena di enterprise “perasaan model bagus” tidak cukup untuk meyakinkan tim risiko.
Contoh konkret: NusantaraMart menguji agen “ReturnGuide”. Mereka membuat dataset evaluasi berisi 300 skenario: barang rusak, salah kirim, lewat masa garansi, promosi tertentu, dan kasus abu-abu. Untuk tiap skenario, tim kebijakan menuliskan jawaban referensi yang dianggap “aman dan benar”. Evaluator otomatis kemudian membandingkan jawaban agen dengan referensi—bukan harus identik, tetapi harus memenuhi kriteria. Ketika skor turun setelah pembaruan model, tim bisa melakukan rollback atau memperbaiki prompt dan retrieval. Ini mirip praktik pengujian regresi di perangkat lunak, hanya saja objeknya adalah perilaku bahasa.
Observabilitas juga membantu mengendalikan biaya. Aplikasi GenAI sering mahal karena pemanggilan model besar, konteks panjang, dan penggunaan alat berulang. Dengan pelacakan, tim bisa melihat titik boros: misalnya agen memanggil pencarian semantik tiga kali padahal satu cukup, atau menggunakan model premium untuk pertanyaan rutin. Dalam konteks efisiensi, wawasan tentang penghematan pemanggilan API dan optimasi biaya menjadi pembicaraan luas di industri. Salah satu referensi yang relevan untuk memperluas konteks adalah ulasan mengenai efisiensi penggunaan OpenAI API, yang menekankan pentingnya memilih model dan pola pemanggilan yang tepat untuk kebutuhan bisnis.
Poin penting lain: evaluasi harus mengikuti perubahan data. Jika kebijakan atau katalog berubah mingguan, dataset uji juga perlu versi dan pembaruan. Inilah mengapa menyatukan data dan AI dalam satu platform membantu—pipeline data yang memperbarui tabel kebijakan dapat memicu pembaruan indeks, lalu memicu ulang evaluasi. Insight finalnya: GenAI yang dapat dipercaya lahir dari disiplin MLOps/LLMOps, bukan dari keberuntungan prompt.
Agentic AI di Databricks: Agent Bricks, AI Playground, dan alur kerja alat untuk otomatisasi enterprise
Jika chatbot adalah “wajah” GenAI, maka agen adalah “tangan”-nya. Sistem agen dirancang untuk menilai situasi, merencanakan langkah, memanggil alat, lalu menyelesaikan tujuan—sering kali tanpa instruksi rinci di setiap langkah. Databricks memperluas area ini lewat pendekatan bertingkat: ada pembangun agen terpandu untuk skenario umum, ada lingkungan prototyping, dan ada jalur kustom untuk tim yang ingin kontrol penuh. Ini membuat adopsi lebih inklusif: perusahaan tidak dipaksa memilih antara “no-code yang terbatas” atau “kode penuh yang mahal”.
Dalam cerita NusantaraMart, agen “StockPilot” bertugas mengurangi kehabisan stok. Ketika ada lonjakan pesanan, agen memeriksa data penjualan real-time, memprediksi kebutuhan berdasarkan model permintaan, lalu membuat rekomendasi reorder. Aksi tidak berhenti pada rekomendasi: agen bisa memanggil API ERP untuk membuat draft purchase order, lalu mengirim notifikasi ke manajer untuk persetujuan. Ini adalah otomatisasi yang memiliki nilai langsung, tetapi juga mengandung risiko jika agen salah mengambil data atau salah menafsirkan aturan.
Di sinilah konsep alat (tools) menjadi penting. Alat adalah fungsi tunggal yang jelas input-output-nya: menjalankan SQL, mengambil dokumen dari indeks vektor, memanggil endpoint CRM, atau mengeksekusi kode di sandbox. Agen menyusun rangkaian alat untuk menyelesaikan tugas. Perbedaan mendasar: alat bersifat stateless dan sempit, sedangkan agen mempertahankan konteks dan bisa melakukan iterasi. Dengan desain yang rapi, organisasi bisa membatasi agen: misalnya, agen hanya boleh membuat draft PO, bukan mengeksekusi pembelian final tanpa persetujuan manusia. Kontrol seperti ini membantu menyeimbangkan otonomi dan tata kelola.
Databricks juga mendorong penggunaan protokol standar untuk menghubungkan alat, sehingga tim tidak membuat integrasi satu-off yang rapuh. Saat agen memanggil alat eksternal, penanganan error menjadi aspek produksi yang menentukan. Timeouts, respons rusak, atau parameter tidak valid harus diperlakukan sebagai kondisi normal, bukan kejadian langka. Praktik yang umum: batasi jumlah panggilan alat per sesi, sediakan fallback (misalnya kembali ke jawaban informatif tanpa tindakan), dan pasang guardrail agar agen tidak mengulang panggilan gagal dalam loop. Dalam perusahaan besar, satu loop seperti itu bisa berarti tagihan komputasi melonjak dan sistem eksternal terbebani.
Selain agen operasional, ada agen analitik yang membantu pengguna non-teknis. Bayangkan kepala toko bertanya, “Mengapa penjualan kategori minuman turun minggu ini?” Agen analitik yang baik akan menarik data promosi, stok, cuaca lokal, dan kompetitor (jika tersedia), lalu menjelaskan dengan narasi yang bisa dipahami. Di sinilah analisis data bertemu kecerdasan buatan: bukan mengganti analis, tetapi mempercepat proses bertanya-cek-ulang yang biasanya memakan waktu. Untuk tim data, pendekatan ini membantu mengurangi antrean permintaan ad-hoc.
Agent Bricks (sebagai pembangun terpandu) relevan untuk organisasi yang ingin cepat sampai ke use case umum seperti asisten pengetahuan dan ekstraksi informasi. AI Playground (sebagai area eksplorasi) memudahkan eksperimen prompt dan agen pemanggil alat, lalu mengekspor kode sebagai titik awal. Sedangkan agen kustom cocok ketika perusahaan punya kebutuhan unik: misalnya orkestrasi multi-agen untuk mengoordinasikan pengiriman, pergudangan, dan customer support dalam satu rangkaian. Insight penutupnya: agen yang berhasil bukan yang paling “pintar”, melainkan yang paling jelas batas wewenangnya dan paling dapat diaudit.
Model, prompt engineering, dan fine-tuning: strategi integrasi GPT-5 dan model open-weight di Databricks
Ekspansi integrasi Databricks tidak bisa dipisahkan dari strategi model. Banyak perusahaan kini menjalankan pendekatan multi-model: model besar untuk pertanyaan kompleks dan pembuatan konten, model lebih kecil untuk klasifikasi cepat atau ringkasan singkat, serta model khusus domain untuk istilah internal. Dengan hadirnya model mutakhir seperti GPT-5 secara native dalam ekosistem Databricks—bersama opsi model open-weight seperti gpt-oss 20B dan 120B—organisasi punya fleksibilitas untuk menyeimbangkan kualitas, biaya, dan kontrol.
Pertanyaan praktisnya: kapan cukup dengan prompt, dan kapan perlu fine-tuning? Prompt engineering biasanya menjadi langkah pertama karena cepat dan murah. Tim dapat menuliskan instruksi yang eksplisit: gaya bahasa, format output, larangan menyebut data sensitif, dan cara mengutip sumber. Di Databricks, prompt dapat dikelola lewat antarmuka prototyping maupun pendekatan berbasis data yang mengoptimalkan prompt secara iteratif. Untuk NusantaraMart, prompt untuk “ReturnGuide” misalnya memaksa model selalu menyebut pasal kebijakan yang relevan dan meminta klarifikasi jika informasi pesanan tidak lengkap. Dengan prompt yang baik, banyak kasus bisa terselesaikan tanpa pelatihan ulang.
Namun prompt punya batas. Bila perusahaan memiliki jargon internal, kode produk, atau struktur dokumen yang sangat khas, fine-tuning atau kustomisasi berbasis data bisa memberi lompatan kualitas. Misalnya, NusantaraMart memiliki ribuan template respons CS yang sudah disetujui legal. Menyetel model agar memahami gaya dan struktur template dapat mengurangi variasi jawaban dan menurunkan risiko. Databricks menyediakan jalur komputasi yang memudahkan fine-tuning yang sepenuhnya kustom, termasuk opsi komputasi GPU tanpa server agar tim tidak perlu mengelola klaster GPU sepanjang waktu. Ini penting karena beban fine-tuning sering bersifat periodik, bukan konstan.
Di sisi lain, fine-tuning bukan peluru perak untuk pengetahuan yang sering berubah. Kebijakan retur yang diperbarui tiap bulan lebih cocok diselesaikan dengan retrieval (RAG) daripada menanamkannya ke bobot model. Kombinasi yang umum adalah: RAG untuk fakta dinamis, fine-tuning untuk gaya, format, dan kebiasaan jawaban. Dengan demikian, agen tetap aktual tetapi juga konsisten. Inilah pola “kecerdasan umum + kecerdasan data”: model membawa kemampuan berbahasa, data perusahaan membawa kebenaran konteks.
Kerja sama bernilai besar dengan OpenAI menunjukkan bahwa Databricks mengejar pengalaman “native” agar pemanggilan model, kontrol akses, dan logging berada dalam satu alur enterprise. Bagi pelanggan besar, ini mengurangi kebutuhan membangun jembatan manual antara gudang data dan penyedia model. Dampaknya terasa pada waktu implementasi: proof-of-concept bisa naik kelas menjadi produksi lebih cepat, karena aspek audit dan governance sudah tersedia.
Meski demikian, organisasi tetap perlu strategi pemilihan model. Tidak semua tugas butuh GPT-5. Banyak workflow bisa berjalan dengan model yang lebih kecil, terutama jika retrieval kuat dan prompt terstruktur. Untuk membantu pengambilan keputusan, tim biasanya membuat matriks internal: kompleksitas pertanyaan, toleransi kesalahan, batas latensi, dan biaya per permintaan. Dari sana, routing model bisa dibuat: pertanyaan sederhana diarahkan ke model ringan, kasus berisiko tinggi ke model premium dengan guardrail lebih ketat. Insight terakhirnya: keberhasilan AI generatif di enterprise ditentukan oleh orkestrasi cerdas—bukan sekadar memilih model paling terkenal.











